Today’s Big Data environment consists of multiple data sources covering various aspects of the business. Enterprise data is most often distributed across disparate information systems, sources and silos, resulting in different types, structures and latencies. Pulling all the data together for fast data access to support mission critical activities, such as data analytics and Business Intelligence (BI) reporting can be very challenging. The traditional approach of building Extract-Transform-Load (ETL) pipelines to get the data into a common format and location where it can be queried is complex, expensive and slow.
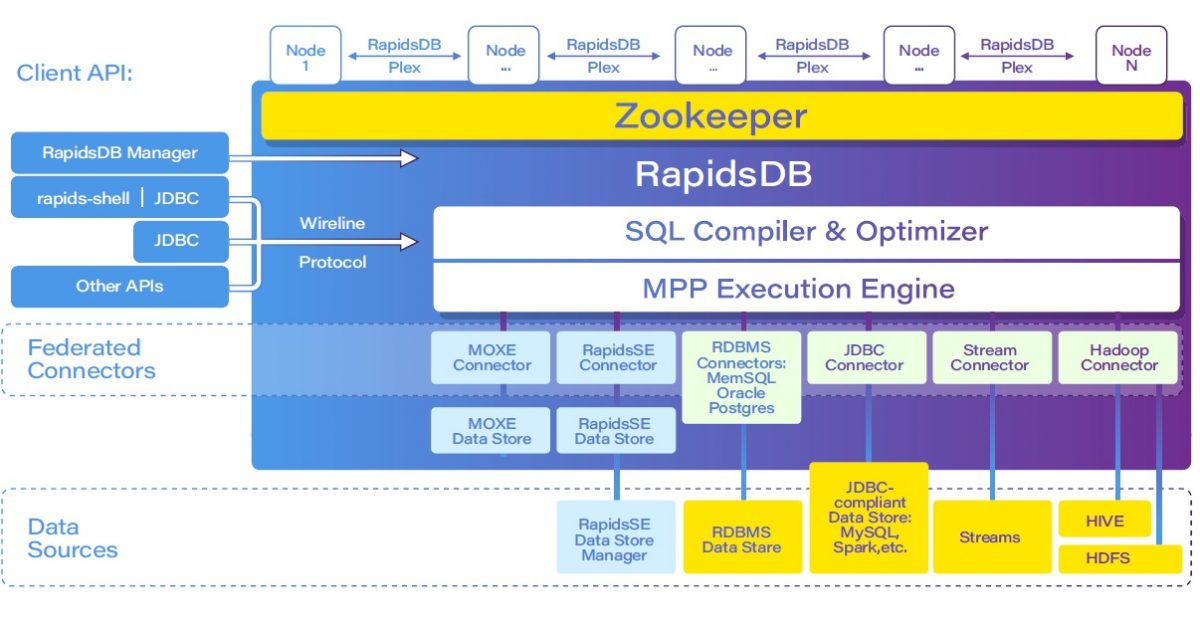
To tackle the live data integration challenge, the Rapids Data Platform (RDP) integrates data at the application query level using a connector-based architecture to separate data storage and compute. At its heart, RapidsDB is a fully distributed, ANSI-SQL compliant, MPP, in-memory and federated query execution system. The RapidsDB Federation Connector system provides an interface by logically grouping a set of one or more dynamically pluggable Connectors, with each Connector responsible for providing direct access to an underlying data source without the need for ETL.
In the digital era, data variety remains one of the biggest big data challenges for many organizations. Different data systems have different data types, such as integer, floating-point number, character, string, etc. The RapidsDB Federation Connectors are responsible for managing the data type conversion between the native data stores and the RapidsDB query engine. Each Connector provides a table-based abstraction over the underlying data source. As long as data can be presented as rows and columns, the RapidsDB Execution Engine can query the data using standard ANSI SQL. Data from multiple sources is transparently integrated and presented to the user as a single, federated database.
The RapidsDB Federation Connector system creates harmony among varying data types across different data management systems and produces a consistent result for queries, regardless of where the data resides. In most cases, queries are generated by applications instead of people. Database administrators (DBAs) or solution architects have written programs querying the data through JDBC or some other interfaces. Different database systems and JDBC drivers behave differently, so users can run into issues when they try to connect their applications to different data sources. Program modification or rewriting is often required, which can be expensive in terms of the time and effort needed as well as the potential for introducing new bugs. RapidsDB federated queries offer a standardized syntax, behavior and connectivity, which abstracts away the complexity of the backend data systems. It allows the underlying data sources to be re-architected without modifying the applications. Different data sources can be substituted according to changing business needs while the application code stays the same. It saves time and cost of data integration and provides the agility that is needed for rapidly changing analytical requirements.
The power of the RapidsDB Federation Connectors also derives from their active involvement in the execution of a query plan. In order to optimize performance, we generally want to have the underlying data source perform as much of the query as possible to reduce the amount of data that has to be transferred over the network and processed by the RapidsDB Execution Engine. This can give much better performance than simply pulling all of the data from the data source and processing it in a main query engine (an approach often used by systems with simple data import APIs or wrappers). For example, when the data source is a relational database such as Oracle, it is typically capable of executing a join on the tables in that data source, or it can filter the data based on predicates in the query. RapidsDB supports an optimization feature called “Adaptive Query Pushdown” to deal with this. With Adaptive Query Pushdown, each Connector involved in the execution of a federated query plan analyzes the plan and decides which operations can be pushed down to the data source and, for the remaining parts of the query, the optimum way to retrieve the data.
Currently, the RapidsDB Federation Connector system provides Connectors for the following data sources:
- MOXE: the internal in-memory data store for RapidsDB
- RDBMS data sources including Oracle, Postgres, MySQL, MemSQL and Greenplum
- Any data source that supports access via JDBC, for example, Spark
- HDFS delimited, Parquet or ORC files, in conjunction with the Hive Metastore or directly against the files in HDFS
- Streams
Connectors are written in Java, and new Connectors can easily be created and added to support new data sources and data formats as they become available. While the Rapids Data team constantly expands the list of available Connectors, users can write their own proprietary Connectors for access to proprietary data stores.
In addition, the RapidsDB Federation Connector system gives the user the abilities to tailor a view on the data in each data source. It provides pseudonyms for data source catalogs, schemas and table names. A DBA or database architect can have multiple options for constructing a “data world” specific to the needs of a particular user or user group, offering power and control to ensure the quality, integrity, discoverability and protection of data.
The RapidsDB Federation system’s ability to pull data from many different data sources into one cohesive source and present a unified view of multiple sources under one set of rules through Connector technology enables users to focus on one SQL dialect, one JDBC system and one set of API behaviors. Complex queries only need to be written once but can be run against any data source without modification, providing consistent result sets regardless of the location of the underlying data with consistent presentation at the maximum speed and minimum cost. This resists vendor lock-in and allows users to focus on where they want to store their data to give them the best overall price-performance while meeting their response-time requirements. They no longer have to be concerned about the impact on applications of moving data off expensive, underperforming data platforms.
The intelligent, connector-based Federation solution empowers enterprises to break data silos and obtain extra insights from the data sources that originally were beyond reach. Compared to the static data consolidation through ETL, federating traditional data at rest, such as Hadoop or relational data, combined with real-time streaming data, such as IoT sensor data or log files, brings the advantage of live data integration. It boosts real-time decision-making by providing a holistic view of the business so that enterprises can truly harvest the value of all data.