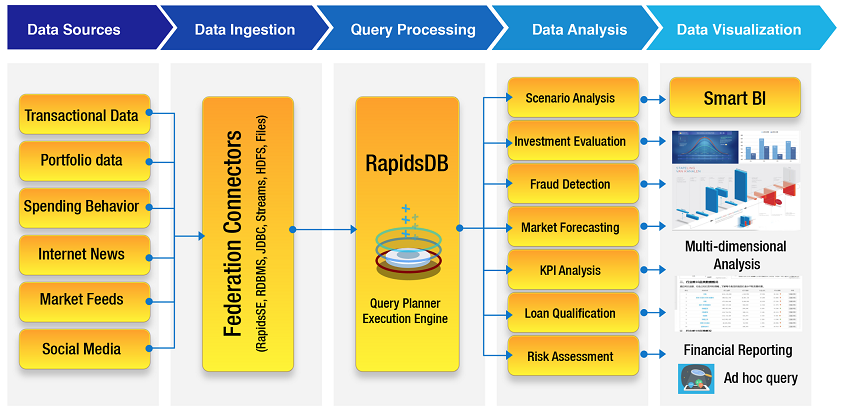
Information digitalization is reshaping the financial world. As the financial markets are moving faster than ever before, technological innovation represented by big data, cloud computing, block chain, and artificial intelligence is becoming the new momentum of the information revolution and provides a new driving force for financial industry transformation. Legacy data architectures can no longer effectively meet the new requirements of financial activities such as risk analysis and management, fraud detection, portfolio management, future market demand prediction and so forth. In the era of big data, financial companies need to leverage the power of new technologies to gain valuable insights from data so that they can develop cost effective and scalable business solutions quickly to achieve competitive advantages.
Current Data Management Challenges for Financial Services
- Legacy data architectures cannot handle large data volumes
- Data silos created by different departments within an organization reduce information transparency and the traditional ETL (extract, transform, and load) approach used to break the barriers is complex, expensive and slow
- Batch processing cannot support real-time decision-making
- Responding to customer queries is slow and costly as traditional data management systems add complexity to the data ecosystem, which requires highly skilled data specialists to perform data analysis
Rapids Data Platform (RDP) Solution
A distributed and in-memory computing architecture to support massive dataset exploration while leveraging the low cost of commodity hardware.
RapidsDB is a distributed, MPP (Massively Parallel Processing), shared-nothing memory database. The disk-free IO eliminates the process of loading data from disk to memory for processing, which contributes to the high-performance data analytic capabilities. The distributed architecture allows horizontal expansion from one node to dozens or even hundreds of nodes based on business needs, which leverages low-cost commodity hardware. The MPP character tackles big data by partitioning the data across multiple nodes and guarantees that the computing and storage resources on each node are independent. RapidsDB can support 100 TB of data analysis in real time. The ability to handle high throughput and high concurrency of big data accelerates data processing and multi-dimensional analysis so that a holistic view of information can be obtained. Actionable business insights can be gained in real time to maximize the return on investment.
A federated heterogeneous data integration system to query data in-place without the need for ETL.
Rapids Federation provides RapidsDB with various external data source connectors, both relational and non-relational, enabling RapidsDB to perform heterogeneous data analysis. Data silos make it prohibitively costly to extract data and undermine the interests of an organization as a whole. The traditional approach of using ETL to get the data into a common format and location where it can be queried is complex, expensive and slow, and often results in multiple out-of-date copies of the data that have to be managed. Through the Rapids Data Connector system, the RapidsDB Execution Engine can get access to the data where it resides without the need for ETL or making additional copies of the data. The data is presented to the user as a single, federated database, where the user can easily identify and combine the data across any of the data sources. In addition, using a feature called “Adaptive Query Pushdown”, each Connector involved in the execution of a query plan analyzes the query plan and decides which parts of the query plan it can push down to the data source or handle within the Connector. As a result, query results and data analysis can be completed in a required time frame in a more cost-efficient way than a traditional ETL approach. It improves data sharing by promoting cross-department operational synergy and overcome challenges posed by disparate data silos across the organization.
A platform that can handle both streaming data and non-streaming (batch) data to support real-time data analysis.
Rapids StreamDB is a distributed, expandable stream database that can continuously and steadily transmit and analyze data within milliseconds. By joining the streaming data with the static data like customer data in one single query, pattern mining can be leveraged in real time to respond immediately to significant events. It enables financial organizations to identify investment opportunities or hidden risk factors in a live market, detect fraud attempts as soon as they occur, qualify loans or credit card applications based on a faster and accurate risk assessment, or respond to customer service calls or ad hoc queries in real time.
An AI supporting component to build machine learning models to achieve high-efficiency and low-latency data processing.
Rapids ParallelR is the AI supporting feature of RapidsDB. It is the distributed, parallel implementation of the R language and the R operating environment integrated within a RapidsDB cluster. It enables users to apply machine learning against data being managed by RapidsDB. Currently it supports 20 popular algorithms in the 4 categories of statistical analysis, ensembles, deep neural networks and dimension reduction. With low-latency and high-efficiency data processing, machine learning models can be used to present exponentially larger sets of data. It builds different scenarios to answer what-if questions in a quick and cost effective way. Advances in AI can learn new patterns and detect new threats to forecast market expectations, reduce investment risks, identify billing and payment errors, and prevent fraudulent activities. Financial institutions can review real-time enhanced data, which provides a holistic view of a business and create more detailed and advanced risk profiles.
A standard ANSI SQL and user-friendly self-service interface to reduce operational complexity and allow business users without subject-matter expertise to be able to access and analyze data.
SQL is the common computer language in the data world. Many business and technical users in the financial industry have already been using SQL skills in their daily work. Even legacy data systems are running hundreds of thousands of lines of SQL code that had been developed and iterated over years. It will be costly if the new architecture has to use a different language and a new workforce with subject-matter expertise has to be developed. The Rapids Data Platform is a unified big data analytical platform with ANSI SQL and JDBC interfaces. Users can use their existing skillset to write simple or complex SQL queries to access data easily without having to worry about the location or format of the data. Dashboards can also be customized to filter, mine, scale, associate, transform, compute and link data to generate reports based on users’ changing needs, providing exploratory analysis capability for end users to find and resolve problems by themselves.
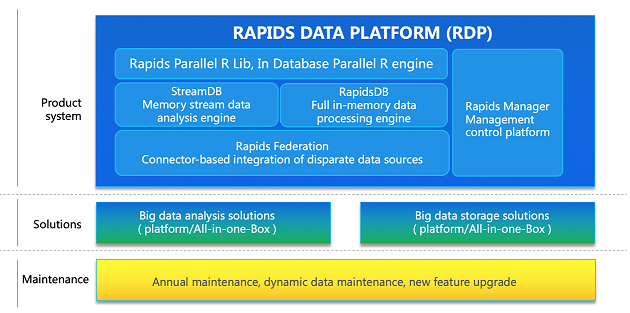
Conclusion:
Financial industry transformation starts with data. Technology innovation is the key to modernize the financial industry to meet the ever growing customer expectations.
Rapids Data Platform is an advanced big data platform dedicated to real-time data analysis. Utilizing the distributed and in-memory computing technology, RapidsDB is the high-performance real-time big data analysis engine that accelerates data processing speed while reducing latency, complexity and O&M cost to the IT department. The unique Rapids Federation uses a connector-based system to integrate various types of data such as streaming data, semi-structured data, Hadoop and conventional data and so forth without the complex, expensive and slow ETL process. Rapids StreamDB provides streaming data analysis and ensures real-time streaming data processing through highly optimized SQL. Rapids ParallelR leverages machine learning algorithms to provide cost-effective AI support. Financial services run on speed. The financial industry solution supported by the unified data architecture of the Rapids Data Platform helps financial organizations process and analyze historical and hot and warm data in real time, detect and mitigate risk in real time, respond to ad hoc queries in real time, and ultimately make business decisions in real time to optimize customer experience and maximize corporate profit.