RapidsDB Product Matrix
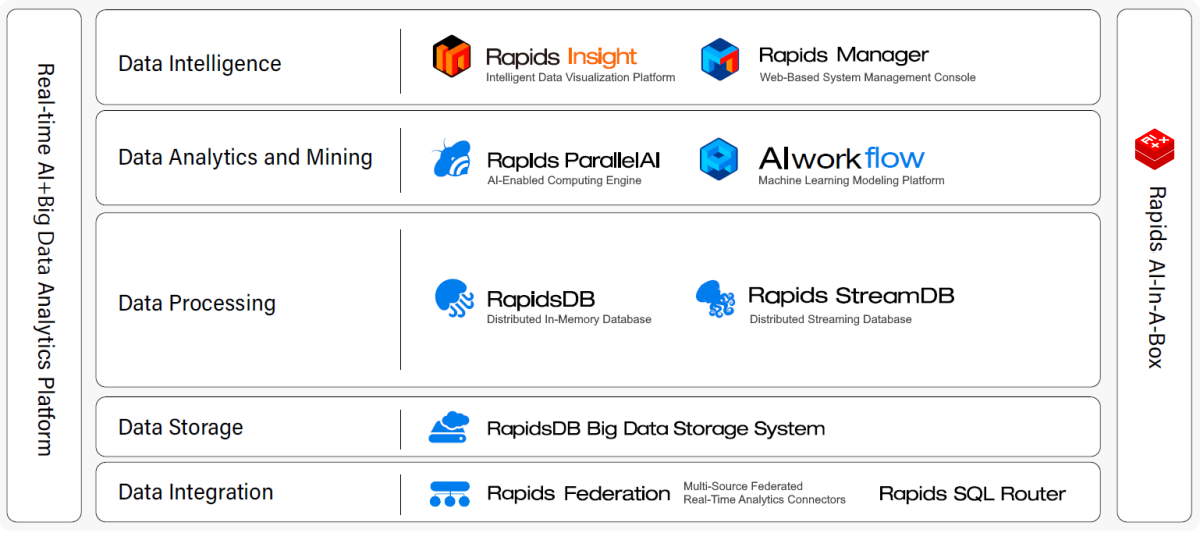
RapidsDB - Distributed, In-Memory, Real-Time Analysis Engine
- Distributed, MPP, shared-nothing, in-memory database
- Unified ANSI SQL query support for multiple data sources
- Adaptive query pushdown and dynamic query optimization
- Supports multiple table joins across nodes
- Supports TPC-H and TPC-DS levels of complicated query analysis
Rapids StreamDB - ISO Standard-Based, In-Memory Streaming Data Processing Engine
StreamDB is an in-memory and distributed stream database that can continuously analyze streaming data within milliseconds. High-velocity data streams (real-time big data) can be distributed to high-speed memory processing clusters to achieve real-time analysis and processing, breaking through the performance bottleneck of the traditional framework of storing data first before getting it processed.
- Millisecond-level real-time data processing and computing
- Fully compatible with ANSI SQL and a variety of window functions
- Incremental data refresh
- Supports multiple data source integration
Rapids Federation - Multi-Origin Federated Real-Time Analytics Connector System
Rapids Federation is a logical grouping of a set of one more RapidsDB Connectors. The federated connector system provides RapidsDB with dedicated or generalized connector components for accessing various data sources.
Through Rapids Federation, RapidsDB becomes an OLTP-and-OLAP compatible hybrid database, which can conduct real-time data processing on top of the OLTP database without the traditional ETL process. This is a very cost-effective way to augment legacy systems as well.
- Federated connector system for accessing various data sources to break data silos
- Supports heterogeneous data integration to analyze structured, semi-structured and unstructured data
- Dispenses with ETL to avoid data architecture changes and data migration risks
- Uses Standard ANSI SQL to query logically consolidated data and provide OLTP and OLAP hybrid support
Rapids ParallelAI- AI-Enabled Big Data Analytics
ParallelAI is an AI-enabled analytics platform with an in-memory, distributed, parallel implementation of the R language and the R operating environment integrated within a RapidsDB cluster. It enables users to apply machine learning against data being managed by RapidsDB.
Rapids ParallelAI currently supports 20 popular algorithms in 6 categories for complex modeling.
- Regression
- Classification
- Clustering
- Dimension reduction
- Ensemble
- Natural language processing
Rapids Hadoop - Enterprise-Grade Big Data Storage Management Engine
Based on open source Apache Hadoop technology, Rapids Hadoop is dedicated to helping enterprises build data lakes in a short period of time through strictly size-controlled installation packages. The pre-loaded Hadoop with optimized configurations ensures fast deployment of large-scale clusters.
Through the federated HDFS Connector, CSV (delimited) Parquet and ORC format data can be extracted from Hadoop and consolidated with other federated data sources including streaming data for real-time big data analysis in RapidsDB.
- Open source-based Hadoop technology that supports batch processing and real-time analysis of heterogeneous big data
- Provides various SQL-on-Hadoop analytical application tools
- Preset optimized Hadoop configuration that promotes high-speed deployment of large-scale clusters
- Supports cloud computing configurations including IaaS, YARN, and Mesos
- Integrates and authenticates various open source ETL and BI applications
- Provides a rich collection of APIs
Rapids Manager - Web-Based System Management Console
Integrated with the Streamhouse Platform, Rapids Manager is a web-based management console that provides a visual interface for users to configure and manage the RapidsDB cluster.
It offers reliable O&M services by automatically monitoring the operation of each module of the RDP system and optimizing clusters to guarantee the maximum performance of the entire analytics platform.
- Graphical interface for query development and execution
- Virtual installation and rapid configurations
- System-level and various RDP components monitoring
- Visualized Rapids Stack service management
- Automatic clustering optimization
- Secondary development support
Rapids AI-In-A-Box - Software & Hardware Integrated All-In-One Machine
Rapids AI-In-A-Box is a software and hardware integrated all-in-one machine that integrates the in-memory, distributed computing and the traditional computing of multi data sources, storage and network systems to achieve a unified management and performance optimization.
- Store and compute with zero latency
- Simple, efficient and low cost
- Easy O&M with visual management interface
- Self-developed software for better control and security
- Out-of-the box design for easy deployment
- High scalability and high throughput